Web scraping con Python: objetos, diccionarios y JSON
La cuarta entrega del #desafíoPython nos deja una aplicación más estructurada y el primer sistema de almacenamiento para los datos capturados.
¿Quieres disfrutar de todo el desafío con los problemas resueltos en vídeo?
Durante 9 horas de vídeo en castellano te cuento todos los detalles de como he creado esta aplicación. Apúntate al curso del Desafío Python
Este es el cuarto artículo de la serie del #desafíoPython. Consulta la primera, la segunda y la tercera parte.
¿Qué hemos conseguido hasta ahora? ¶
Teníamos pendiente alcanzar el hito 4 del proyecto que nos habíamos marcado en la planificación inicial del trabajo.
Estamos en la versión 0.3.1, cuyo código puedes encontrar en GitHub.
¿Qué dificultades nos hemos encontrado? ¶
Puedes ver los detalles de este desafío con todos los problemas resueltos y la aplicación real funcionando en el curso en vídeo (9 horas)
Más que dificultades, estamos ante la constante duda sobre si debemos avanzar más en la refactorización del código que ejecuta las acciones o bien dejarlo como está e ir dando forma a las necesidades del proyecto.
Programación orientada a objetos ¶
En este punto si hemos incorporado ya la programación orientada a objetos para dar una mayor claridad a todo el conjunto. No sabía que iba a hacerlo ya, me pareció esencial en este punto.
Es cierto que nuestros datos obtenidos del scraping son un diccionario y no un modelo formal, pero al menos todo el proceso de gestión si lo hemos transformado. Esto nos ayuda a separar responsabilidades y facilita que vayamos incorporando nuevas funcionalidades.
Creamos la siguiente estructura:
IvooxScraperClient: Cliente de conexión a Ivoox para capturar la información y devolver un recurso donde poder extraer información. Hereda la responsabilidad de la función obsoletaget_url_content.Storage: Almacena y lee los datos guardados, aunque esto segundo aún no lo necesitamos.Ranker: La clase responsable de gestionar el recurso y convertirlo en una lista de diccionarios. Es una extensión de nuestra antigua funciónget_podcasts.
Así que al final, en nuestro “main”, que aún llamamos app.py sólo tenemos esto:
podcasts = Ranker('internet-tecnologia',445,3).build()
Storage.save('storage/ranking.json', podcasts)
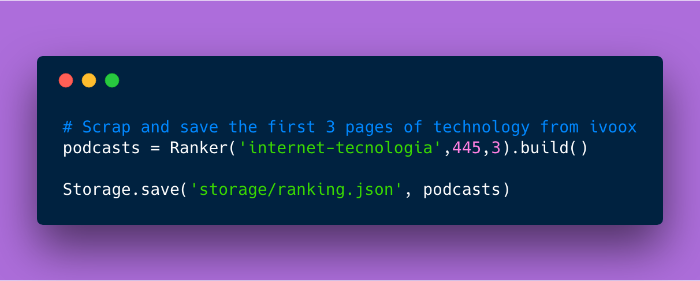
Bonito, ¿verdad? :)
Guardando los datos, ¿para qué? ¶
Nos beneficiamos del uso de la potente librería json de la librería standard de Python. Es muy potente y nos convierte listas y diccionarios en un string de formato JSON (y viceversa) con asombrosa facilidad.
Al guardar los datos la codificación daba problemas con las tildes y las eñes. Un clásico.
def save(filename, data):
with open(filename, 'w') as file:
json.dump(data, file, ensure_ascii=False)
En este extracto de la clase Storage puedes ver un método estático para almacenar la información en un fichero. Nada complejo, salvo el parámetro ensure_ascii=False que evita que se escapen los caracteres no-ASCII (documentación).
Ahora surge una pregunta. Con los datos almacenados en storage/ranking.json ¿qué podemos hacer?
Está claro que los vamos a mostrar en alguna parte, es el compromiso de los hitos siguientes, pero, ¿y si almacenamos también una clave temporal para construir un histórico? ¿Tal vez podamos prescindir de la descripción y colocar simplemente un enlace? Es un dato que no capturamos en este momento.
Dependencias de otras librerías ¶
Al no usar la extensión Python de Visual Studio Code enseguida verás que algunas librerias importadas no son necesarias en según que ficheros, porque no se usan. Utilizando otro editor o IDE seguramente no tendríamos este problema.
Recuerda que vimos este tema en el primer artículo de la serie, porque la extensión parecía tener un bug con el linter instalado para corregir de forma estática el código escrito.
¿Cuando completaremos el hito 5 del proyecto? ¶
Nos marcamos esto:
Hito 5. Mostrar la información almacenada de forma sencilla
El texto era deliberadamente ambiguo, porque realmente podríamos considerarlo ya ejecutado haciendo un pprint(Storage.load('storage/ranking.json') . Evidentemente aquí hablábamos de incorporar una librería que nos permitiera mostrar la información en una web.
Utilizaremos un microframework para generar una web. Es un punto al que estaba deseando llegar. Me parece que la transición entre nuestra lógica y backend hacia la resolución en web es muy evidente y fácil de ejecutar.
Seguramente con algo como Flask, será muy sencillo de obtener. Podríamos pensar en algo más full stack como Django, pero una de las premisas de este proyecto era mantenerlo lo más sencillo posible.
Sólo queremos acceder a una página y listar los resultados guardados en orden. Sin complicaciones, de momento, baby steps lo llaman a esto :)
Recursos para lograrlo ¶
Primero dejamos algunos recursos sobre lo que visto en la ejecución del hito anterior que nos encontramos por sorpresa.
- Programación orientada a objetos en Python: Python.org.ar, AprenderPython o InteractivePython.
- Reading and Writing Files in Python
- Python JSON
Aparte de los recursos que hemos visto en anteriores artículos, donde también se tratan estos conceptos.
Y sobre lo que tenemos por delante:
- Microframeworks web: Flask y Bottle
- Varios recursos sobre Flask
- Curso en codigofacilito
- Introducción a Flask
¿Qué tal te ha ido? ¶
Cuéntanos como te va con esta aventura. Utiliza los comentarios o en twitter con el hastag #desafioPython.
Escrito por:

Daniel Primo
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.